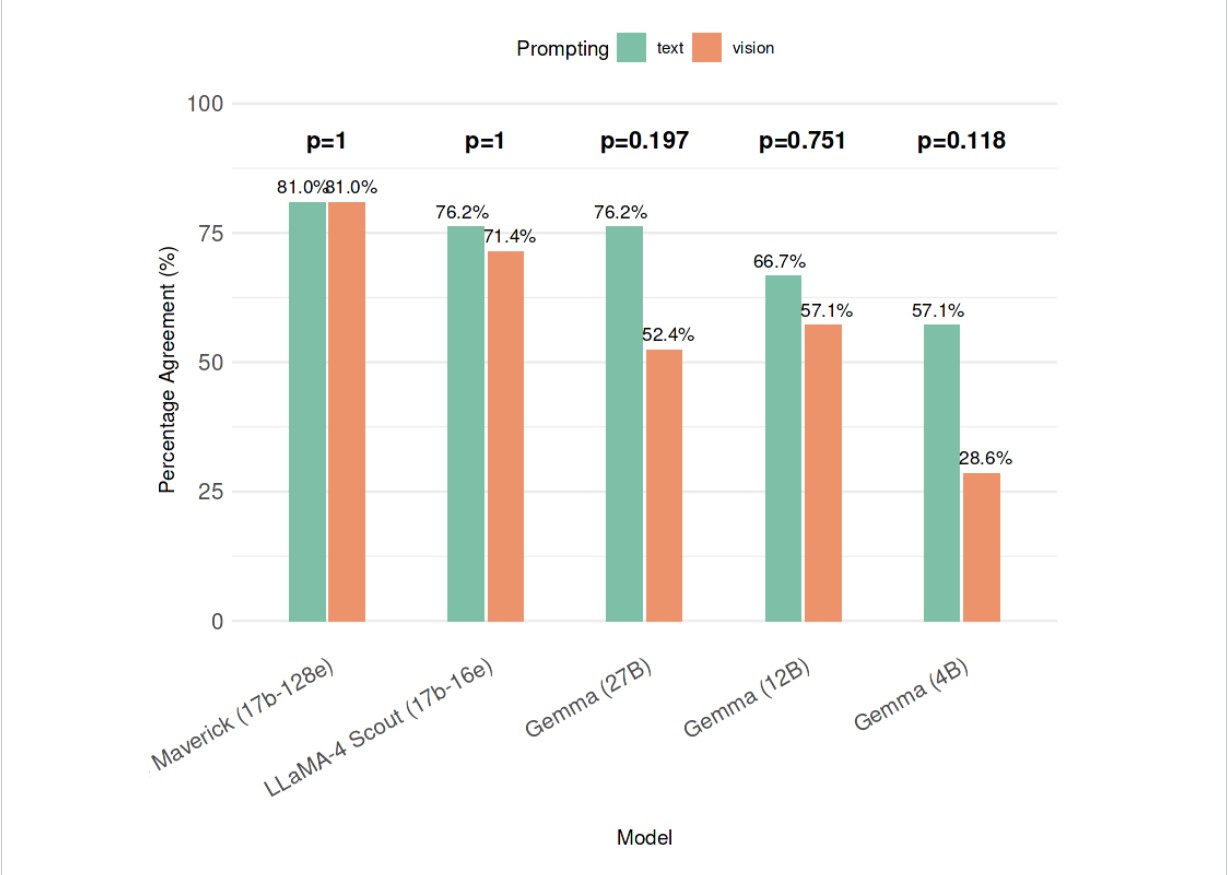
Saman Rashid, MBBS1, Ismail S. Bahaaeldeen, MD2, Joel Richter, MD2 1Karachi Medical and Dental College, Lexington, KY; 2University of Kentucky, Lexington, KY Introduction: The functional lumen imaging probe (EndoFLIP) is a novel tool for evaluating esophageal diseases. Recent guidelines (Dallas Consensus) provide structured algorithms for interpreting EndoFLIP data, but applying them can be challenging, especially in centers without dedicated esophageal teams. Large language models (LLMs), capable of understanding unstructured natural language, have shown utility in similar clinical reasoning tasks. More recently, vision-language models have emerged as a more convenient option, able to interpret image-based prompts with minimal or no textual explanation—potentially streamlining algorithm-based diagnostics. This study aims to evaluate the performance of text-based versus image-based prompting for interpreting EndoFLIP data using consensus algorithms. Methods: We created 21 simulated cases using EndoFlip metrics across seven diagnostic categories, modeled after real patients from our esophageal disease center, which were evaluated by five LLM of varying sizes. Image-based prompts used visual representations of the consensus algorithms and tables, while text-based prompts included detailed manual descriptions of diagnostic criteria. Prompts were iteratively refined to optimize diagnostic accuracy and ensure model comprehension. Model outputs were compared to expert diagnosis, with percent agreement and diagnostic accuracy calculated. Results: Table 1 presents sample cases and model outputs. LLaMA-4-Maverick achieved the highest agreement with 81% accuracy for both text and image based prompts (Figure 1). In contrast, smaller models like gemma-4b showed the lowest image-based agreement (28.6%) compared to 57.1% with text input. Although differences between prompt modalities were not statistically significant due to smaller sample size, trends favored text input. Discussion: EndoFLIP interpretation using LLMs is feasible. While vision-based prompting offers convenience, it underperformed in comparison to text based inputs, particularly in smaller models. Further improvements are expected with refined prompt engineering and few-shot examples. Refinement may lead to LLMs serving as the real time diagnostic assistants in esophageal motility evaluation. A key strength of our approach is the use of open-source models deployable locally, preserving patient privacy.
Figure: Figure 1: Agreement rates and statistical comparison of text based vs. vision based prompting across all models
Figure: Table 1: Sample cases and model responses including the model justification for the selected diagnosis.
Disclosures: Saman Rashid indicated no relevant financial relationships. Ismail Bahaaeldeen indicated no relevant financial relationships. Joel Richter indicated no relevant financial relationships.
Saman Rashid, MBBS1, Ismail S. Bahaaeldeen, MD2, Joel Richter, MD2. P4911 - Automated Interpretation of EndoFLIP Metrics Per Dallas Consensus Using Text- and Image-Based LLM Prompting, ACG 2025 Annual Scientific Meeting Abstracts. Phoenix, AZ: American College of Gastroenterology.