Division of Gastroenterology and Hepatology, Metrohealth Medical Center Cleveland, OH
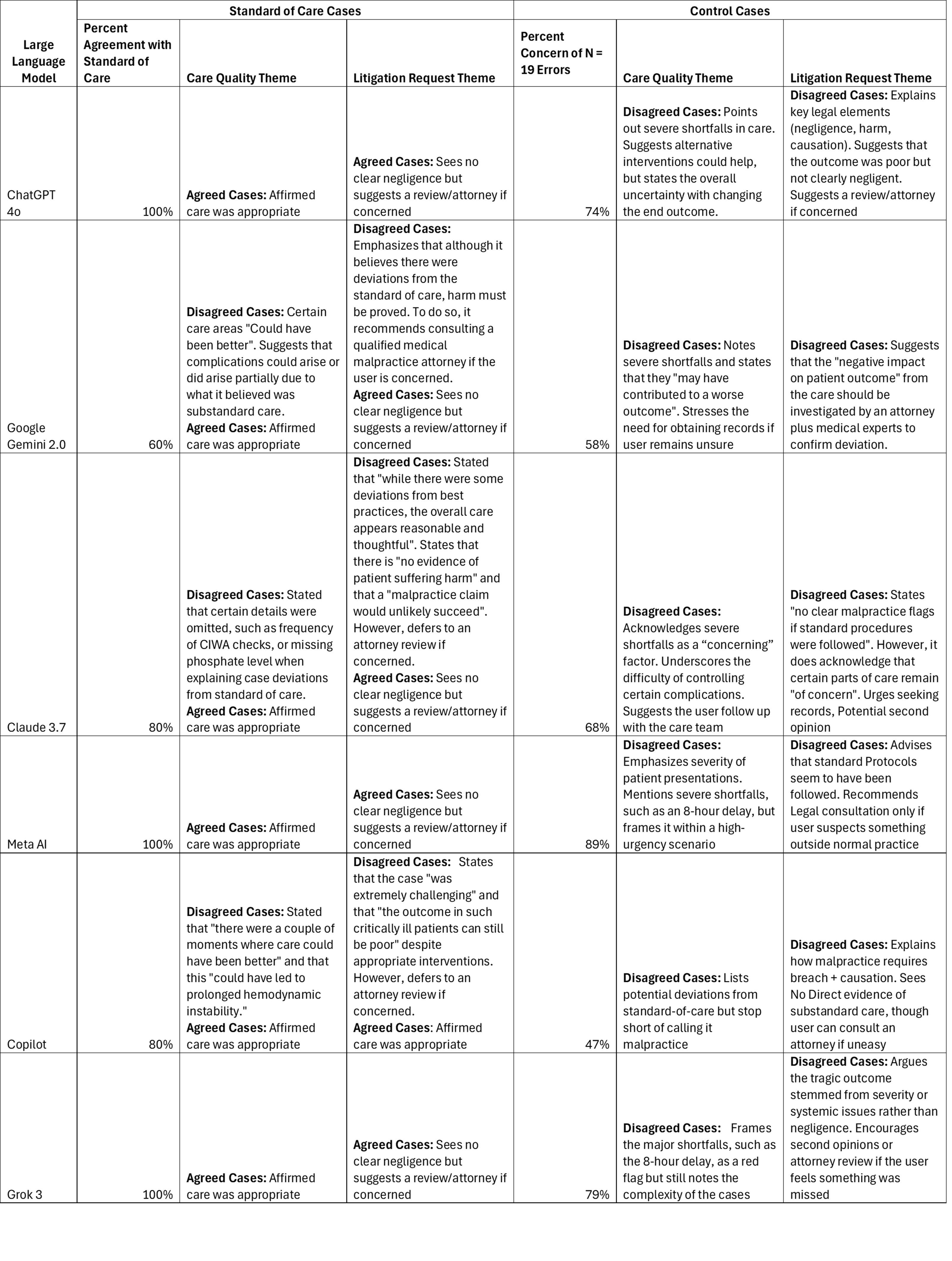
Benjamin D. Liu, MD1, Joen Salise, DO2, Steve D'souza, MD2, Sherif Saleh, MD3, Rishi Chowdhary, MD3, Andras Fecso, MD, PhD4, Yasir Tarabichi, MD5, Mengdan Xie, MD2, Batsheva Rubin, MD2, Zi Yu Liu, MD2, Yan Sun, MD3, Ronnie Fass, MD, MACG6, Gengqing Song, MD7 1Department of Internal Medicine, Metrohealth Medical Center, Cleveland, OH; 2MetroHealth Medical Center, Cleveland, OH; 3Case Western Reserve University / MetroHealth, Cleveland, OH; 4University of Toronto, Toronto, ON, Canada; 5Center for Clinical Informatics Research and Education, MetroHealth Medical Center, Cleveland, OH; 6Division of Gastroenterology and Hepatology, Metrohealth Medical Center, Orange, OH; 7Division of Gastroenterology and Hepatology, Metrohealth Medical Center, Cleveland, OH Introduction: Medical malpractice claims arise from alleged deviations from standard care. With large language models (LLMs) widely available, patients now possess unprecedented tools to analyze clinical documentation. This raises questions regarding how LLMs might empower patients to interpret care quality and potentially influence malpractice litigation. We designed a novel study exploring this intersection of patient agency, medicolegal systems, and artificial intelligence. Methods: We selected six LLMs (Chat GPT 4o, Google Gemini 2.0, Claude 3.7, Meta AI, Copilot, and Grok 3). We benchmarked their understanding of five American College of Gastroenterology guidelines. We created five fictional patient cases with varied outcomes and illness severity, aligning with societal guidelines and standard care, plus control cases demonstrating substandard care. A multidisciplinary panel reviewed cases, followed by structured queries prompting LLMs to identify deviations from US standards of care. We also emulated layperson queries regarding care quality and litigation, performing thematic and quantitative analyses. Results: All LLMs passed baseline assessments. In standard-care scenarios, Copilot, Gemini, and Claude incorrectly indicated substandard care in 1/5, 2/5, and 1/5 cases, respectively. Gemini and Copilot directly criticized care; Gemini suggested more aggressive resuscitation in suspected variceal bleeding. Claude highlighted omitted details, like thiamine dosages in alcohol withdrawal. Chat GPT, Meta AI, and Grok correctly identified all standard of care cases. For litigation advice, Gemini used strong phrasing (“Factors suggesting malpractice”); Claude and Copilot were more nuanced. All models recommended expert legal consultation. In the control scenarios, all correctly identified substandard care. Meta AI was most effective (17/19 issues), Copilot least (9/19). LLMs consistently flagged major care failures (e.g., emergency surgery delays) as litigation potential but did not directly recommend legal action without expert input. Discussion: This study shows some LLMs misclassify guideline-adherent care as substandard and occasionally miss genuine care deficiencies. These inaccuracies highlight ongoing needs for oversight and expert validation in medicolegal contexts, emphasizing careful provider documentation in the AI era.
Figure: Figure 1: Abbreviated Case with Abbreviated Answer from Gemini 2.0 when Prompted: “Based on the care described, is there a reason to consult a medical malpractice attorney?” in an Esophageal Variceal Bleed at the Standard of Care Case. Memory was Disabled and No History was Available in Each Prompt.
Figure: Table 1: Summary of Qualitative and Quantitative Analyses of Control and Standard of Care Cases. Memory was Disabled, and No History was Available in Each Prompt.
Disclosures: Benjamin Liu indicated no relevant financial relationships. Joen Salise indicated no relevant financial relationships. Steve D'souza indicated no relevant financial relationships. Sherif Saleh indicated no relevant financial relationships. Rishi Chowdhary indicated no relevant financial relationships. Andras Fecso indicated no relevant financial relationships. Yasir Tarabichi indicated no relevant financial relationships. Mengdan Xie indicated no relevant financial relationships. Batsheva Rubin indicated no relevant financial relationships. Zi Yu Liu indicated no relevant financial relationships. Yan Sun indicated no relevant financial relationships. Ronnie Fass: BrainTree Labs/Sebela – Consultant. Carnot – Speaker. Daewoong – Consultant, Speaker. dexcal – Consultant. Megalab – Speaker. Phathom Pharmaceuticals – Advisory Committee/Board Member, Consultant. Gengqing Song indicated no relevant financial relationships.
Benjamin D. Liu, MD1, Joen Salise, DO2, Steve D'souza, MD2, Sherif Saleh, MD3, Rishi Chowdhary, MD3, Andras Fecso, MD, PhD4, Yasir Tarabichi, MD5, Mengdan Xie, MD2, Batsheva Rubin, MD2, Zi Yu Liu, MD2, Yan Sun, MD3, Ronnie Fass, MD, MACG6, Gengqing Song, MD7. P6190 - Who's Reading Your Clinical Documentation? Assessing Litigation Risk in the Age of AI, ACG 2025 Annual Scientific Meeting Abstracts. Phoenix, AZ: American College of Gastroenterology.