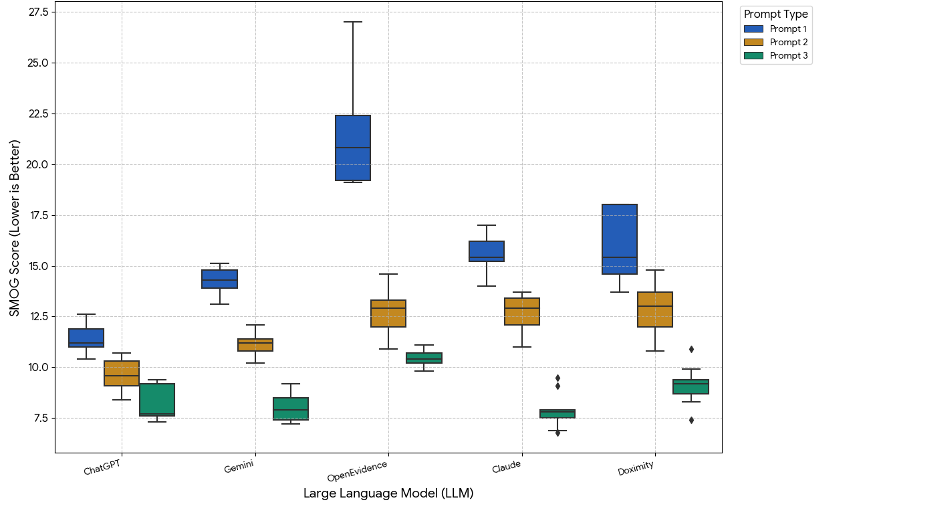
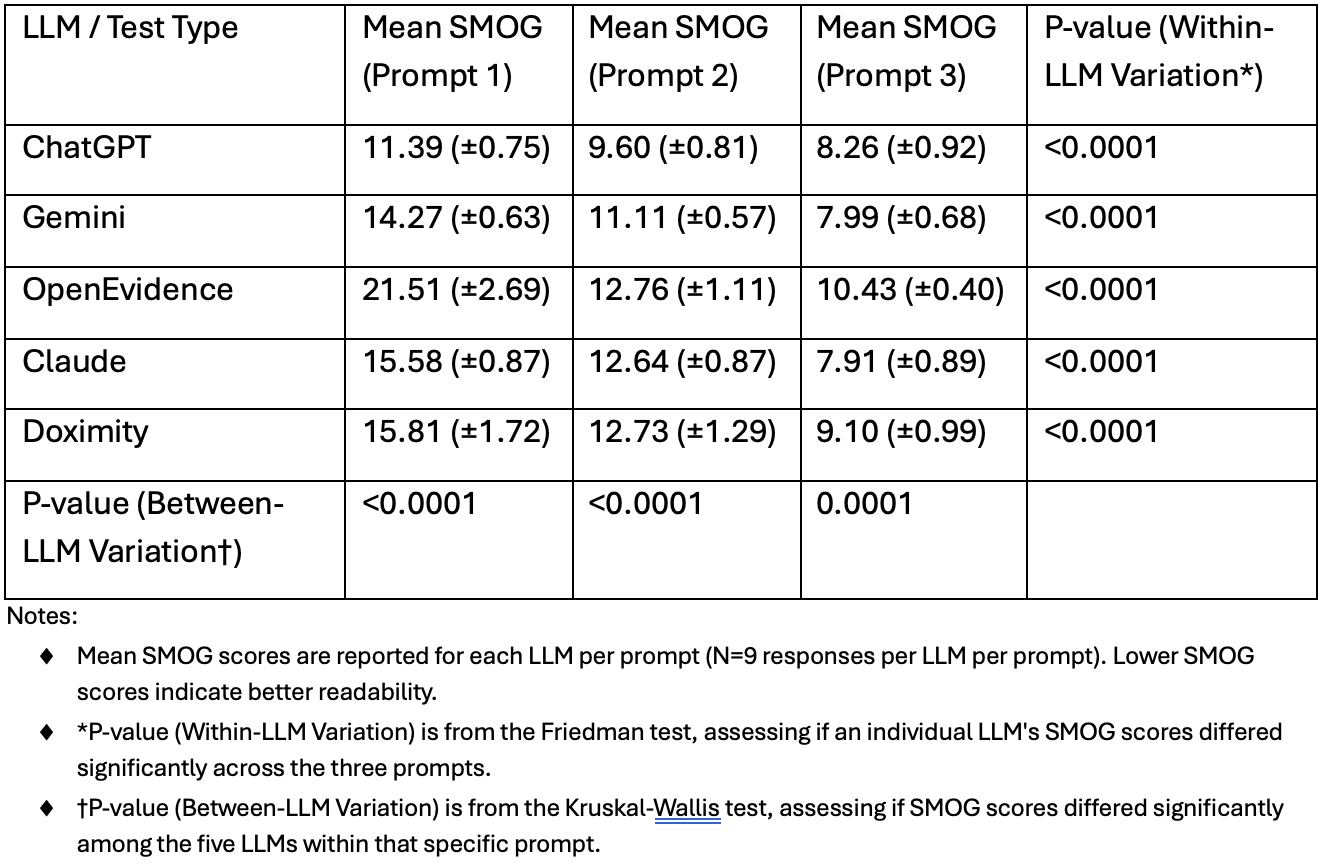
Aishwarya Gatiganti, MD1, Husayn F. Ramji, MD2, Jacob Lampenfeld, MD1, Corinne Zalomek, MD1, Brandy H. Sullivan, MD, MPH3, Stephanie Mrowczynski, BS, MD1, Larry Z. Zhou, MD4, Anveet Janwadkar, MD1, Sharan Poonja, MD5, Pooja Arumugam, MD1, Luis A.. Morales, MD, MS5, Chandler Gilliard, MD, BS2, Shaquille Lewis, MD1, Matthew Houle, MD1, Matthew B.. Alias, MD, MS5, Peng-Sheng Ting, MD1, Sarah Glover, DO5 1Tulane School of Medicine, New Orleans, LA; 2Tulane University School of Medicine, New Orleans, LA; 3Tulane Medical Center, Kenner, LA; 4Tulane Medical Center, Metairie, LA; 5Tulane University, New Orleans, LA Introduction: Large language models (LLMs) are increasingly applied in healthcare and their ability to generate educational materials for complicated conditions, such as inflammatory bowel disease (IBD). It is important to assess whether such LLM-generated materials align with established health literacy standards, as recommended by the National Institutes of Health (NIH), and Agency for Healthcare Research and Quality (AHRQ). This study evaluates the readability of LLM-generated materials for patients with IBD and evaluates whether these emerging technologies can consistently deliver accessible health information. Methods: Five LLMs (ChatGPT 4o, Gemini 2.5, Claude 4.0, Doximity GPT, and OpenEvidence) were asked three prompts: Prompt 1 (“What is [condition]?”), Prompt 2 (“I am a patient that was just diagnosed with [condition]. Explain that to me in simple terms”), and Prompt 3 (“Explain [condition] to a patient at a 6th grade reading level or below”). The conditions were IBD, Crohn’s, and Ulcerative Colitis. The same prompt was repeated three times for every condition on each LLM, for a total of 135 outputs. Readability was assessed with the Simple Measure of Gobbledygook (SMOG) index via the Sydney Health Literacy Lab (SHeLL) Health Literacy Editor. The Shapiro-Wilk test was used to assess normality, followed by appropriate statistical analysis to assess for within-model differences across prompts and between-model differences for the same prompt, with post-hoc analysis and a p-value of < 0.05 considered statistically significant. Results: Across all five LLMs, both the within-model and between-model differences were found to be statistically significant for each prompt (p< 0.001) with readability improving from Prompt 1 to 3. Although ChatGPT averaged higher readability than other LLMs in prompts one and two, and Claude in prompt three, none consistently provided materials below a 6th grade reading level. OpenEvidence had the most complex outputs, averaging the highest SMOG scores consistently across prompts. Discussion: This study illustrates that, in their current models, the five tested LLMs generate outputs at a higher reading level than recommended for healthcare material for patients with IBD, even when prompted to specifically do so. Further training of LLMs is indicated to ensure they consistently provide accessible health information to patients.
Figure: Table 1: SMOG Readability Scores and Statistical Significance
Figure: Figure 1: SMOG Readability Scores by LLM and Prompt Type
Disclosures: Aishwarya Gatiganti indicated no relevant financial relationships. Husayn Ramji indicated no relevant financial relationships. Jacob Lampenfeld indicated no relevant financial relationships. Corinne Zalomek indicated no relevant financial relationships. Brandy Sullivan indicated no relevant financial relationships. Stephanie Mrowczynski indicated no relevant financial relationships. Larry Zhou indicated no relevant financial relationships. Anveet Janwadkar indicated no relevant financial relationships. Sharan Poonja indicated no relevant financial relationships. Pooja Arumugam indicated no relevant financial relationships. Luis Morales indicated no relevant financial relationships. Chandler Gilliard indicated no relevant financial relationships. Shaquille Lewis indicated no relevant financial relationships. Matthew Houle indicated no relevant financial relationships. Matthew Alias indicated no relevant financial relationships. Peng-Sheng Ting indicated no relevant financial relationships. Sarah Glover: Janssen – Consultant.
Aishwarya Gatiganti, MD1, Husayn F. Ramji, MD2, Jacob Lampenfeld, MD1, Corinne Zalomek, MD1, Brandy H. Sullivan, MD, MPH3, Stephanie Mrowczynski, BS, MD1, Larry Z. Zhou, MD4, Anveet Janwadkar, MD1, Sharan Poonja, MD5, Pooja Arumugam, MD1, Luis A.. Morales, MD, MS5, Chandler Gilliard, MD, BS2, Shaquille Lewis, MD1, Matthew Houle, MD1, Matthew B.. Alias, MD, MS5, Peng-Sheng Ting, MD1, Sarah Glover, DO5. P6183 - Health Literacy in the Age of Artificial Intelligence: Readability of LLM-Generated Materials for Patients With IBD, ACG 2025 Annual Scientific Meeting Abstracts. Phoenix, AZ: American College of Gastroenterology.

 photo")