University of Pittsburgh Medical Center Pittsburgh, PA
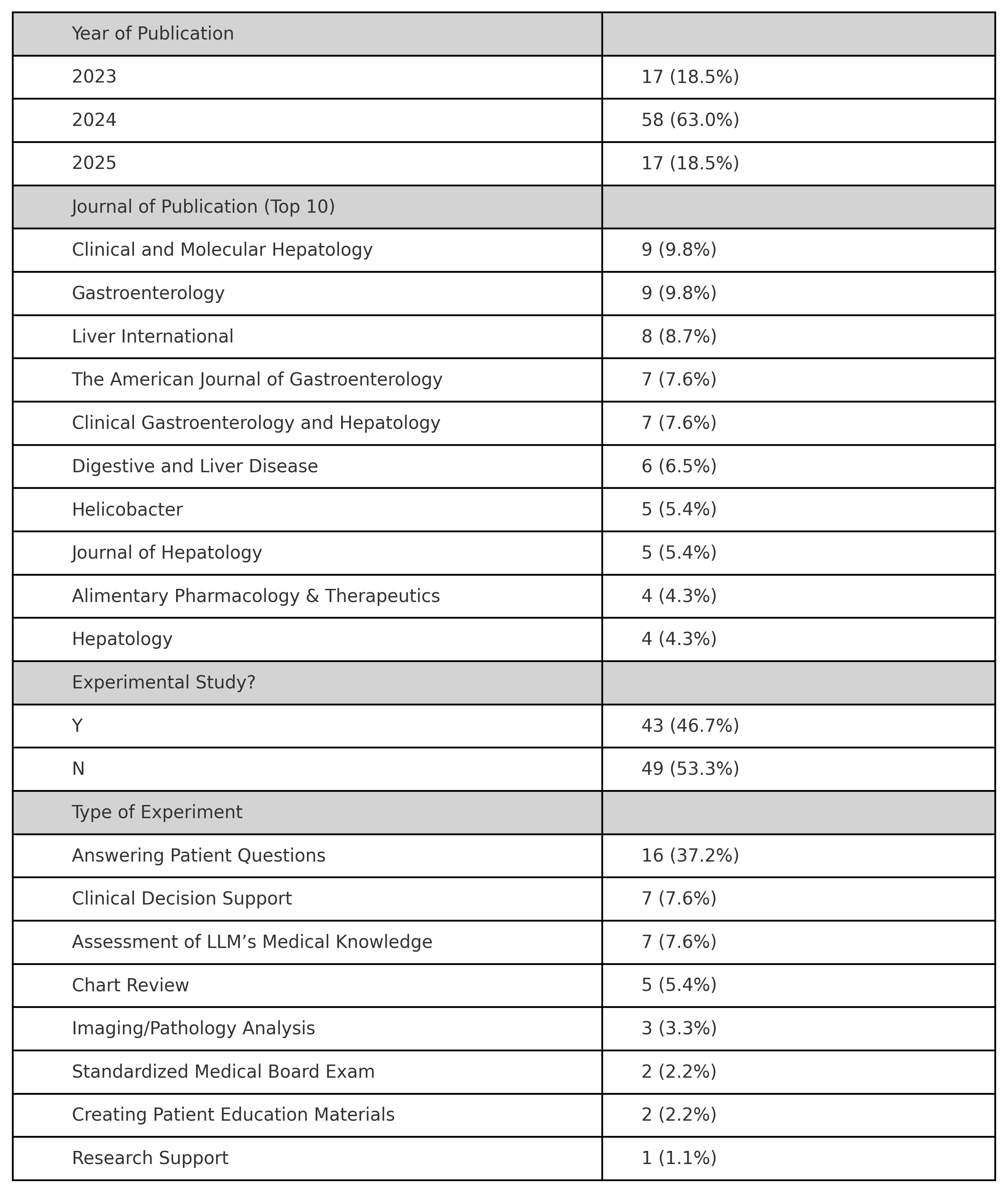
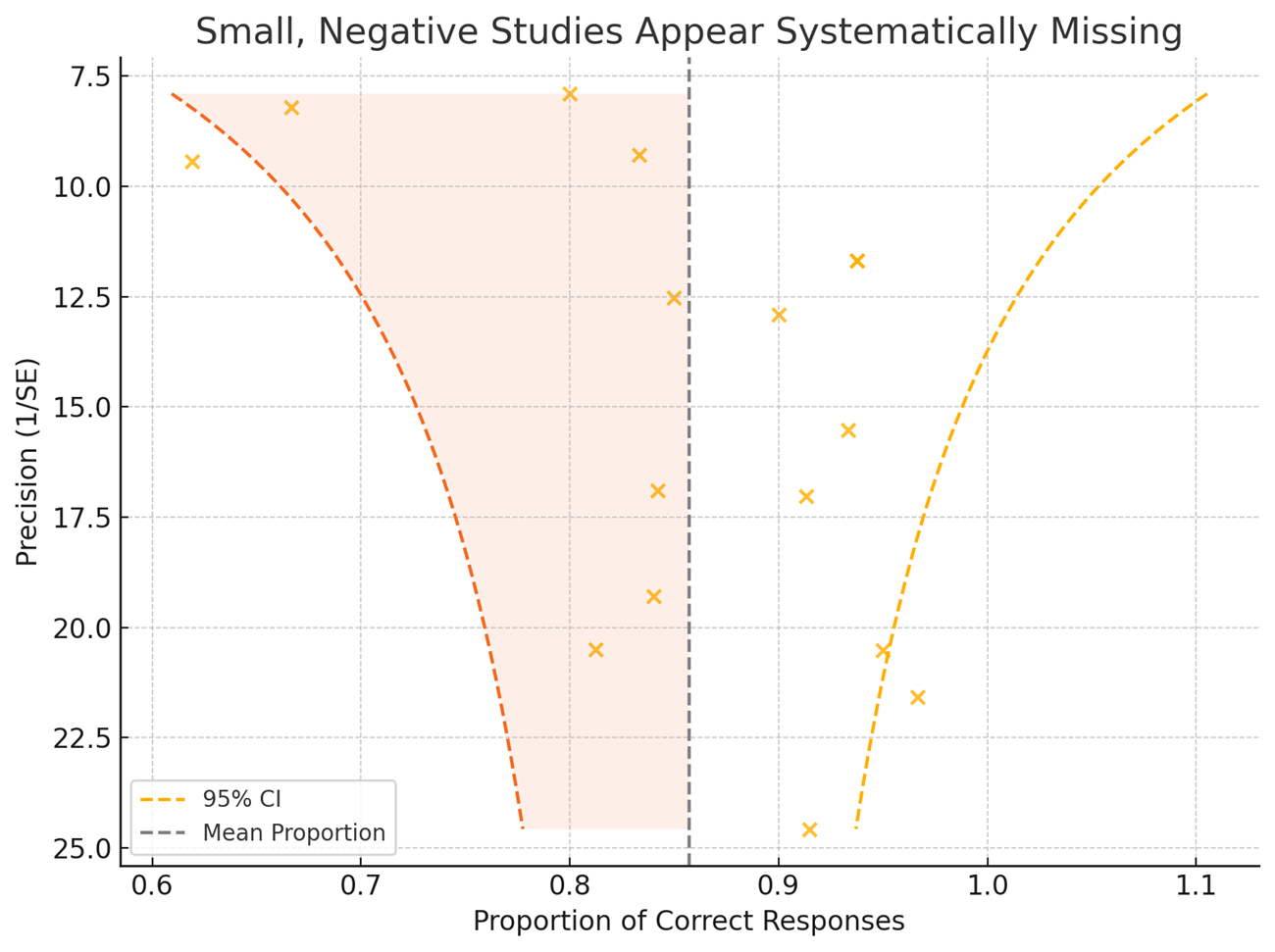
Varun Jain, MD1, Tyler M. Berzin, MD2, Thomas Gonzales, MD1, Anisha Jain, BS3, Sultan Mahmood, MD1 1University of Pittsburgh Medical Center, Pittsburgh, PA; 2Beth Israel Deaconess Medical Center, Boston, MA; 3University of Pittsburgh School of Medicine, Pittsburgh, PA Introduction: There is growing interest in the use of artificial intelligence (AI) in clinical medicine, with a particular focus on large language models (LLMs) and their utility in patient communication and clinical decision-making. In gastroenterology (GI), numerous studies have evaluated LLMs, reflecting excitement around the technology. However, this enthusiasm raises concerns about potential bias toward positive findings. We conducted a systematic review to assess the presence of publication bias in experimental studies evaluating LLM applications in GI. Methods: We performed a systematic review using PubMed, Embase, and Cochrane Reviews to identify studies on LLMs published in the top 50 GI journals ranked by h-index between 2022 (the release year of ChatGPT) and April 2025. Each paper was evaluated as experimental or not, (i.e. testing LLMs’ ability to respond to questions vs. discussing the implications of LLMs in GI). For experimental studies, we classified the study by experiment type and identified the most frequent experimental designs. Funnel plot analysis and Egger’s regression test were used to assess publication bias for the most common experiment type. Results: We identified 92 eligible papers, 43 of which were experimental. The most common experiment types were: (1) answering representative patient questions (n=16), (2) assessing LLMs’ understanding of clinical guidelines (n=7), and (3) evaluating LLMs’ ability to support clinical decision (n=7). OpenAI’s ChatGPT was the most frequently evaluated LLM. We further analyzed studies assessing LLMs responses to representative patient questions. Funnel plot analysis showed asymmetry, with a lack of small studies reporting lower effect sizes, consistent with presence of publication bias. Egger’s test yielded a statistically significant result (p = 0.027), also indicating evidence of publication bias. Discussion: Our analysis suggests the presence of publication bias in GI-LLM research, particularly in studies assessing patient-facing applications. The under-reporting of negative findings could skew clinical perceptions of LLM efficacy and safety, potentially leading to premature or overconfident clinical integration. Greater transparency and publication of null or negative results are needed to ensure a balanced evidence base. Limitations of this study include the relatively small sample size of GI-specific LLM studies and the focus on high-impact journals, which may further amplify bias.
Figure: Table One. Descriptive data of eligible studies.
Figure: Figure One. Funnel plot of 16 studies showing asymmetry consistent with publication bias. Dashed lines represent 95% confidence limits around the mean effect size.
Disclosures: Varun Jain indicated no relevant financial relationships. Tyler Berzin: Boston Scientific – Consultant. Medtronic – Consultant. Wision AI – Consultant. Thomas Gonzales indicated no relevant financial relationships. Anisha Jain indicated no relevant financial relationships. Sultan Mahmood indicated no relevant financial relationships.
Varun Jain, MD1, Tyler M. Berzin, MD2, Thomas Gonzales, MD1, Anisha Jain, BS3, Sultan Mahmood, MD1. P1915 - Time for a Gut Check: Publication Bias in GI-Focused LLM Research, ACG 2025 Annual Scientific Meeting Abstracts. Phoenix, AZ: American College of Gastroenterology.

 photo")