Tulane University School of Medicine New Orleans, LA
Husayn F. Ramji, MD1, Aishwarya Gatiganti, MD2, Jacob Lampenfeld, MD2, Corinne Zalomek, MD2, Brandy H. Sullivan, MD, MPH3, Stephanie Mrowczynski, BS, MD2, Larry Z. Zhou, MD4, Anveet Janwadkar, MD2, Sharan Poonja, MD5, Pooja Arumugam, MD2, Luis A.. Morales, MD, MS5, Chandler Gilliard, MD, BS1, Shaquille Lewis, MD2, Matthew Houle, MD2, Matthew B.. Alias, MD, MS5, Peng-Sheng Ting, MD2, Sarah Glover, DO5 1Tulane University School of Medicine, New Orleans, LA; 2Tulane School of Medicine, New Orleans, LA; 3Tulane Medical Center, Kenner, LA; 4Tulane Medical Center, Metairie, LA; 5Tulane University, New Orleans, LA Introduction: The accessibility to large language model (LLM) generated materials has increased dramatically over the past two years. Patients and practitioners alike can utilize it to create educational materials in clinic and on the wards. Given the nation’s health literacy gap, it is the recommendation of the Agency for Healthcare Research and Quality (AHRQ) that all healthcare materials be written at a sixth grade reading level or below. However, there is little evidence if LLM-generated materials are meeting this benchmark, especially for materials targeting patients with digestive or liver conditions. This project analyzes the readability of LLM-generated materials in the field of gastroenterology (GI) and hepatology across multiple LLMs.
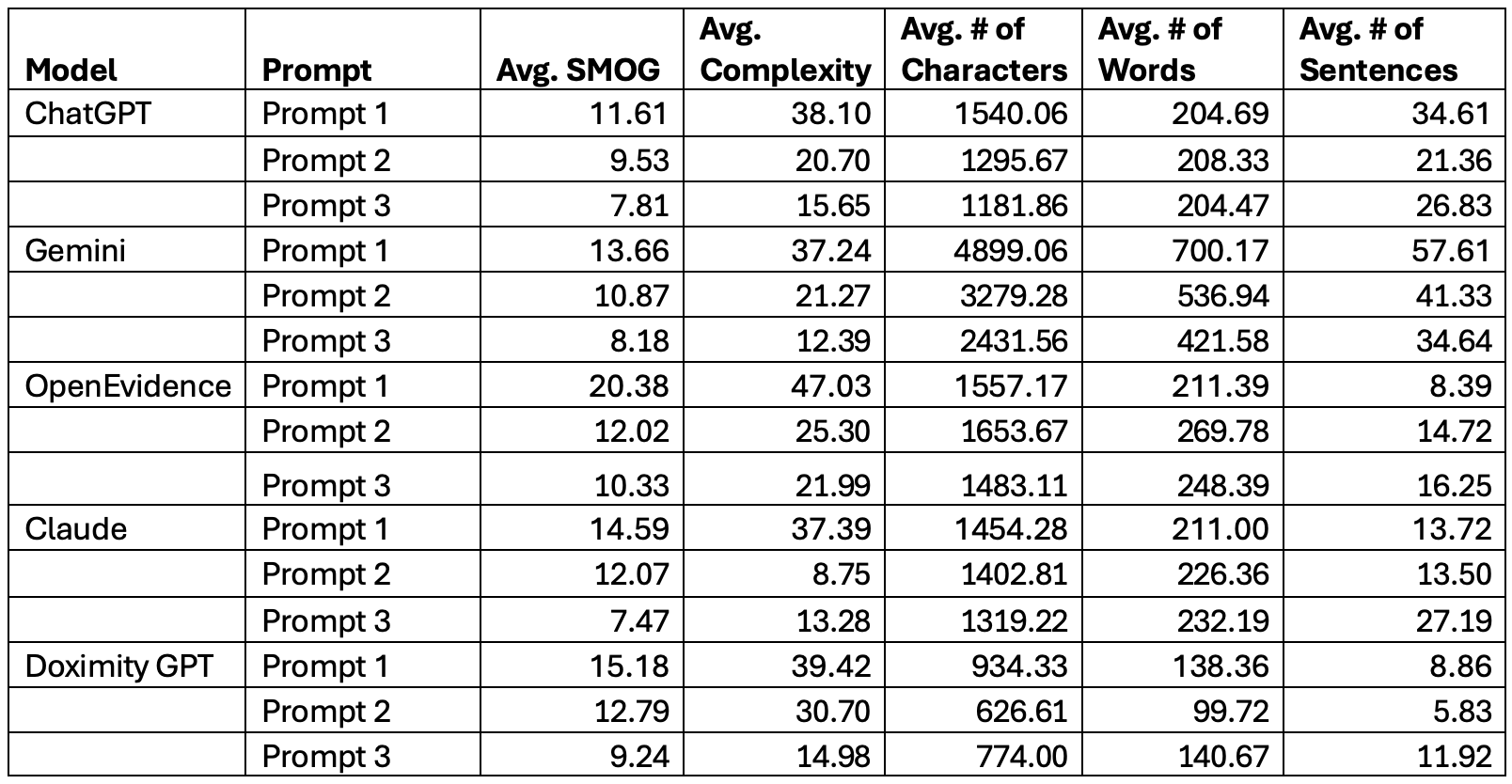
Methods: ChatGPT 4o, Gemini 2.5 Pro, Claude Sonnet 4, OpenEvidence, and Doximity GPT were all asked three prompts: Prompt 1 (“What is [condition]?”), Prompt 2 (“I am a patient that was just diagnosed with [condition]. Explain that to me in simple terms.”), and Prompt 3 (“Explain [condition] to a patient at a 6th grade reading level or below.”). Each LLM was asked the same prompt three times for twelve common gastrointestinal and liver conditions, yielding a total of 540 outputs. The “readability” of the outputs was assessed with the Sydney Health Literacy Lab Health Literacy Editor tool, which provides the validated SMOG index to assess the readability of healthcare materials. Analysis involved normality testing, followed by significance testing for within-model comparisons across prompts, and between-model comparisons for each prompt, with p< 0.05 being deemed statistically significant.
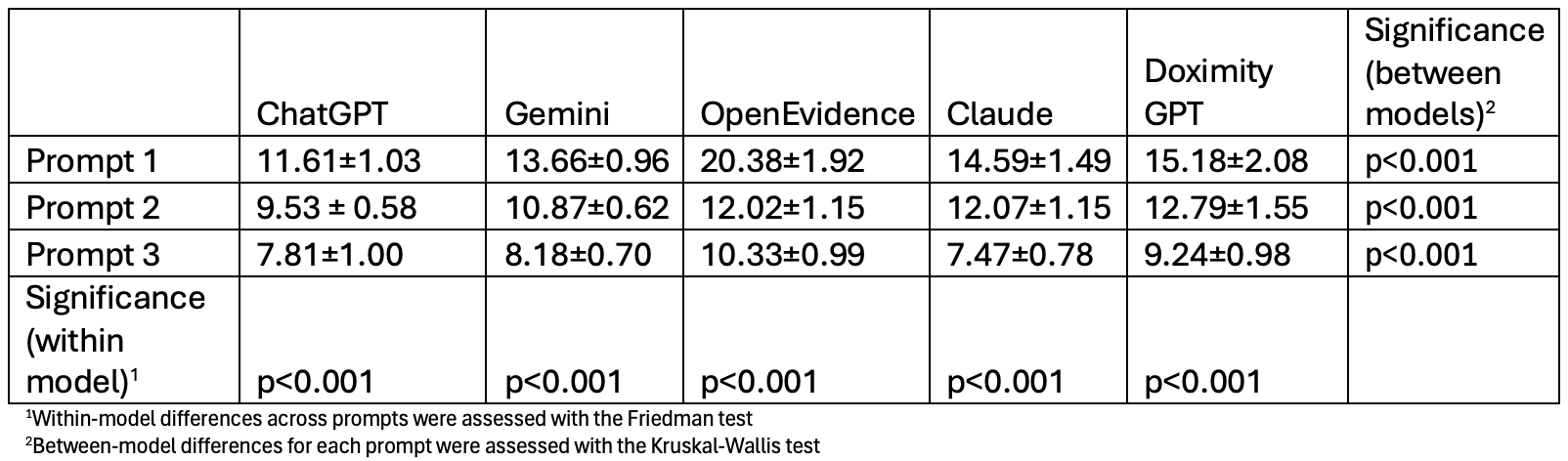
Results: Every LLM showed statistically significant differences between-models (p< 0.001), with statistically significant levels of improvement in readability from Prompt 1 to Prompt 3 within-models (p< 0.001). However, no LLM consistently produced material at a 6th grade reading level for any prompt variation. Claude had the lowest average SMOG index in Prompt 3 (7.5 ± 0.8), followed by ChatGPT (7.8 ± 1.0), and Gemini (8.2 ± 0.7). Discussion: This project is one of the first to analyze the readability of LLM-generated materials in the field of gastroenterology and hepatology. At this time, none of the leading LLMs consistently met the goal of providing materials at a 6th grade level or below but utilizing more specific prompts may aid in reaching this goal. At this time, we recommend cautious but deliberate use of LLMs in the field of gastroenterology and hepatology.
Figure: Table 1: Summary Statistics by LLM per Prompt
Figure: Table 2: Average Readability Score by LLM, with within-model and between-model comparisons
Disclosures: Husayn Ramji indicated no relevant financial relationships. Aishwarya Gatiganti indicated no relevant financial relationships. Jacob Lampenfeld indicated no relevant financial relationships. Corinne Zalomek indicated no relevant financial relationships. Brandy Sullivan indicated no relevant financial relationships. Stephanie Mrowczynski indicated no relevant financial relationships. Larry Zhou indicated no relevant financial relationships. Anveet Janwadkar indicated no relevant financial relationships. Sharan Poonja indicated no relevant financial relationships. Pooja Arumugam indicated no relevant financial relationships. Luis Morales indicated no relevant financial relationships. Chandler Gilliard indicated no relevant financial relationships. Shaquille Lewis indicated no relevant financial relationships. Matthew Houle indicated no relevant financial relationships. Matthew Alias indicated no relevant financial relationships. Peng-Sheng Ting indicated no relevant financial relationships. Sarah Glover: Janssen – Consultant.
Husayn F. Ramji, MD1, Aishwarya Gatiganti, MD2, Jacob Lampenfeld, MD2, Corinne Zalomek, MD2, Brandy H. Sullivan, MD, MPH3, Stephanie Mrowczynski, BS, MD2, Larry Z. Zhou, MD4, Anveet Janwadkar, MD2, Sharan Poonja, MD5, Pooja Arumugam, MD2, Luis A.. Morales, MD, MS5, Chandler Gilliard, MD, BS1, Shaquille Lewis, MD2, Matthew Houle, MD2, Matthew B.. Alias, MD, MS5, Peng-Sheng Ting, MD2, Sarah Glover, DO5. P1914 - Benchmarking the Readability of LLM-Generated Patient Materials in Gastroenterology and Hepatology, ACG 2025 Annual Scientific Meeting Abstracts. Phoenix, AZ: American College of Gastroenterology.


.jpg "Husayn F. Ramji, MD (he/him/his) photo")