Keck School of Medicine of the University of Southern California Arcadia, CA
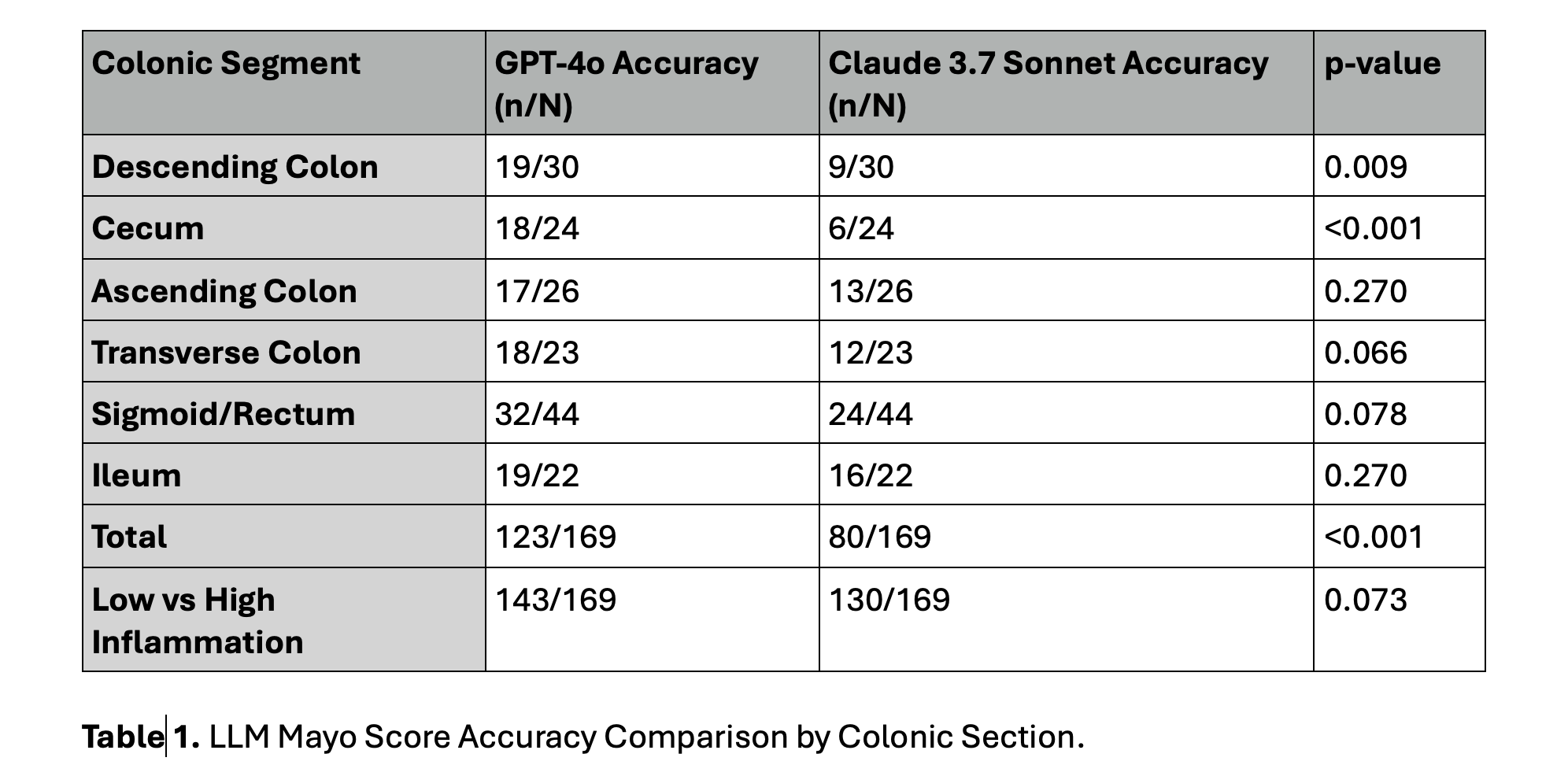
Jordan Stellern, MD1, Sean Dewberry, MD2, Adriana Shen, MD2, Susie Lee, MD2, Alejandro Delgado, MD2, Maziar Amini, MD2, Charlotte Ching, MD2, James Buxbaum, MD2, Sarah Sheibani, MD2, Ara Sahakian, MD2 1Keck School of Medicine of the University of Southern California, Arcadia, CA; 2Keck School of Medicine of the University of Southern California, Los Angeles, CA Introduction: The Mayo endoscopic subscore is a critical tool for assessing disease severity in Ulcerative Colitis (UC), guiding treatment and monitoring response. Traditional scoring relies on subjective endoscopist interpretation, leading to interobserver variability. This study evaluates GPT-4o and Claude 3.7 Sonnet, large language models (LLMs), in determining Mayo subscores from colonoscopy images, with an emphasis on potential clinical and low-resource utility. Methods: Colonoscopy images from 50 patients with confirmed UC were analyzed; all images were deidentified prior to analysis. Images from each colon segment (cecum, ascending, transverse, descending, sigmoid/rectum, and ileum) were extracted from reports and presented to GPT-4o and Claude 3.7 Sonnet in a chat interface, prompting the model to assign a Mayo subscore (0–3). Model-assigned scores were compared to those assigned by the performing endoscopist (gold standard). Accuracy was defined as the proportion of model-assigned scores matching the endoscopist’s. Segment-specific accuracy was calculated, and models were assessed on their ability to distinguish between low (Mayo 0–1) and high (Mayo 2–3) inflammation. Student’s t-tests were used to compare differences in accuracy between the models. Results: GPT-4o showed strong performance across all segments: descending colon (19/30), cecum (18/24), ascending (17/26), transverse (18/23), sigmoid/rectum (32/44), and ileum (19/22). Claude 3.7 Sonnet demonstrated lower accuracy: descending colon (9/30), cecum (6/24), ascending (13/26), transverse (12/23), sigmoid/rectum (24/44), and ileum (16/22). Overall, GPT-4o was significantly more accurate (123/169 [72.8%]) than Claude Sonnet 3.7 (80/169 [47.3%], p< 0.001), with significant differences in the descending colon (p=0.009) and cecum (p=0.000). Both models were similarly effective in differentiating low vs high inflammation (GPT-4o: 143/169 [84.6%], Claude: 130/169 [76.9%], p=0.073). Discussion: GPT-4o outperformed Claude Sonnet 3.7 in accurately assigning Mayo subscores, particularly in key segments. Both LLMs effectively distinguished low from high inflammation, suggesting potential to aid treatment stratification and decision-making—especially in settings lacking expert interpretation. Further development and validation are needed for clinical integration.
Figure: Table 1. LLM Mayo Score Accuracy Comparison by Colonic Section.
Disclosures: Jordan Stellern indicated no relevant financial relationships. Sean Dewberry indicated no relevant financial relationships. Adriana Shen indicated no relevant financial relationships. Susie Lee indicated no relevant financial relationships. Alejandro Delgado indicated no relevant financial relationships. Maziar Amini indicated no relevant financial relationships. Charlotte Ching indicated no relevant financial relationships. James Buxbaum: Boston Scientific – Consultant. Olympus – Consultant. Sarah Sheibani: Johnson and Johnson – Speakers Bureau. Ara Sahakian: Boston scientific – Consultant. Olympus medical – Consultant.
Jordan Stellern, MD1, Sean Dewberry, MD2, Adriana Shen, MD2, Susie Lee, MD2, Alejandro Delgado, MD2, Maziar Amini, MD2, Charlotte Ching, MD2, James Buxbaum, MD2, Sarah Sheibani, MD2, Ara Sahakian, MD2. P5407 - AI-Assisted Mayo Endoscopic Scoring in Ulcerative Colitis: A Comparative Analysis of GPT-4o and Claude 3.7 Sonnet, ACG 2025 Annual Scientific Meeting Abstracts. Phoenix, AZ: American College of Gastroenterology.