Sinai Hospital of Baltimore, The George Washington University Regional Medical Campus Baltimore, MD
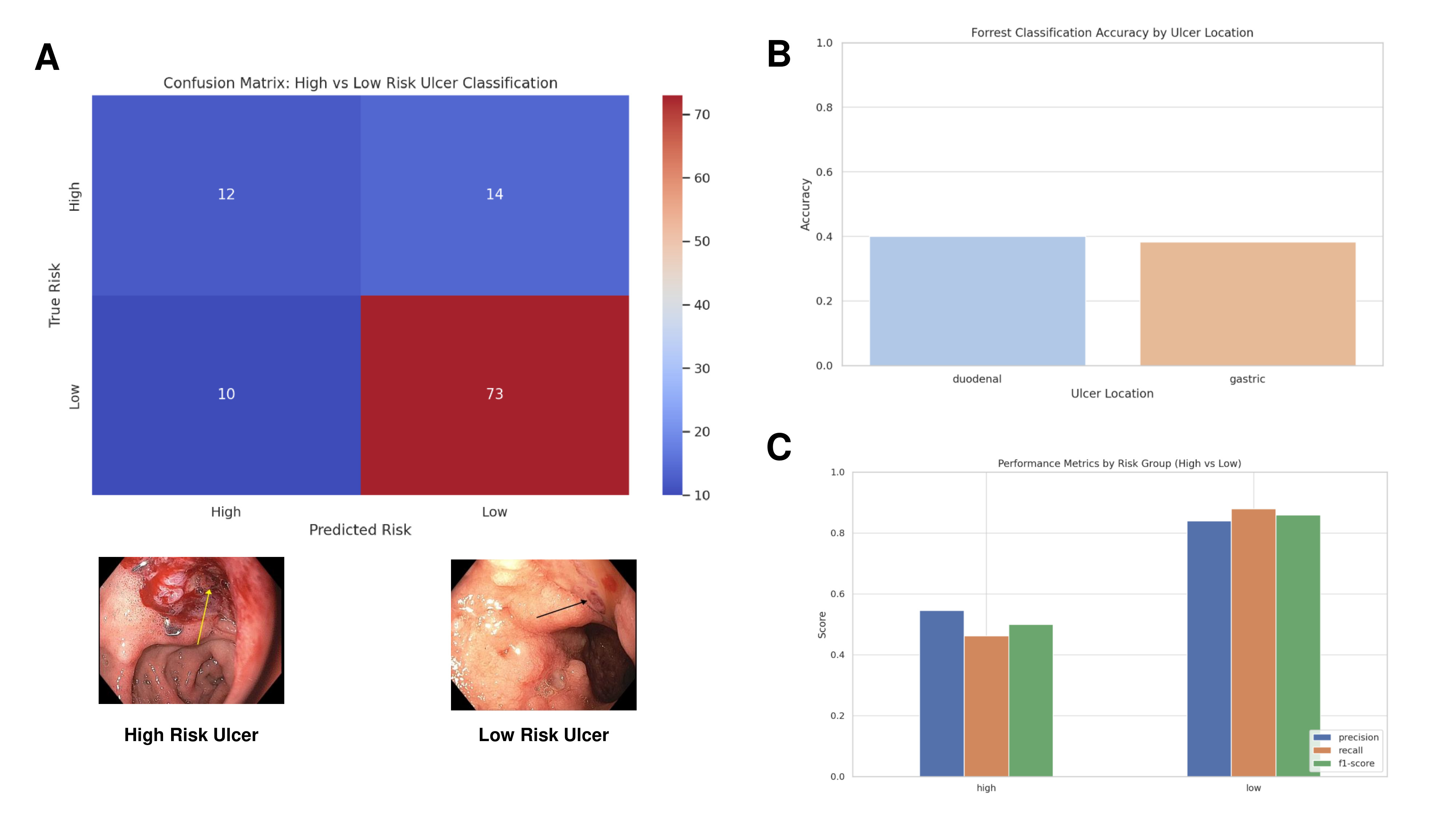
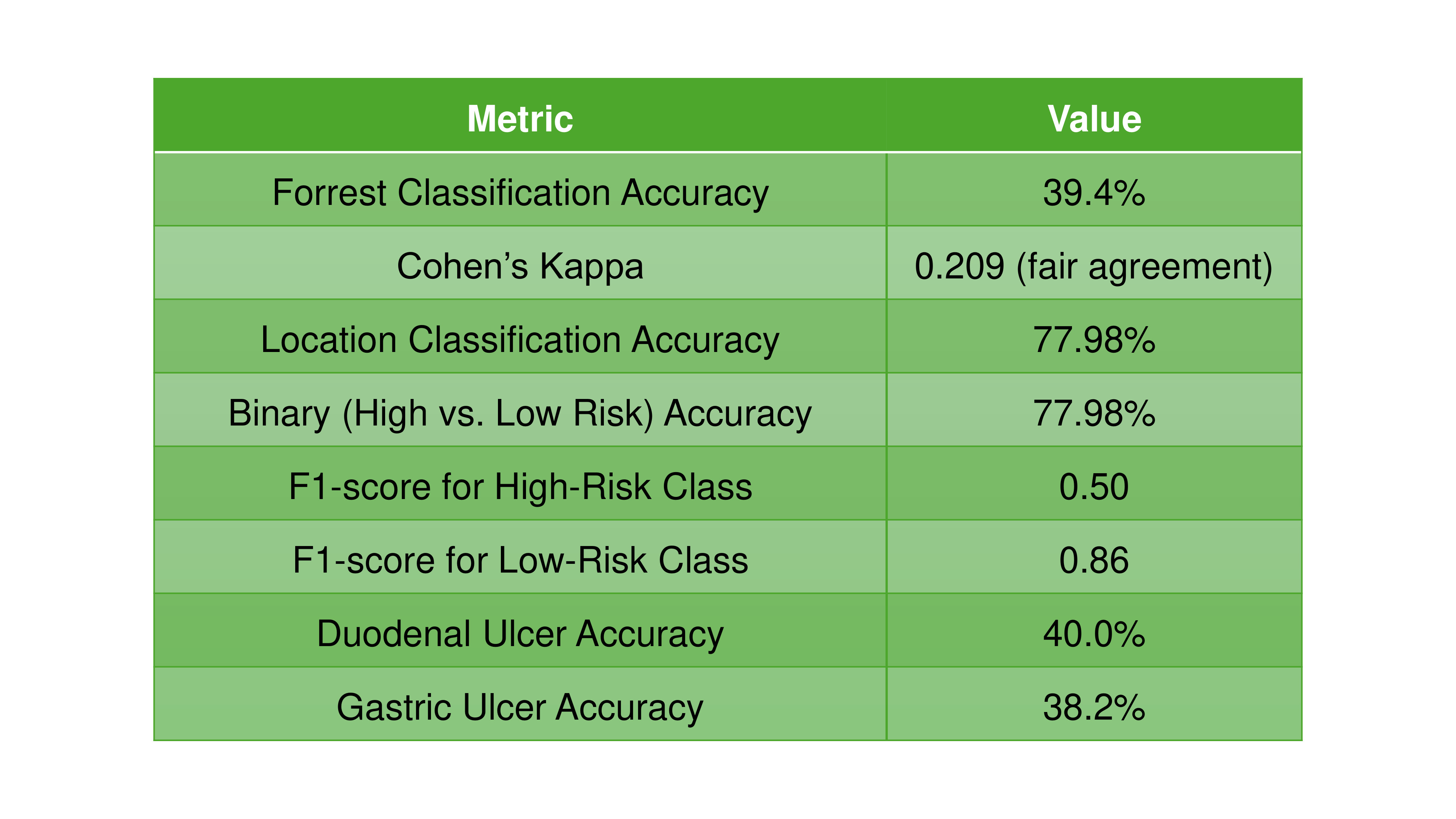
Taha Bin Arif, MBBS, MD1, Tahir Shaikh, MD1, Bedoor Alabbas, MD1, Ruchita Jadhav, MBBS, MD, MPH1, Nimra Hasnain, MBBS, MD2 1Sinai Hospital of Baltimore, The George Washington University Regional Medical Campus, Baltimore, MD; 2Luminis Health Anne Arundel Medical Center, Annapolis, MD Introduction: Artificial Intelligence, particularly large language models like ChatGPT-4o, is transforming healthcare by enhancing medical education and supporting diagnostics. ChatGPT-4o, capable of interpreting both text and images, offers precise diagnostic suggestions. This study aimed to assess its accuracy in Forrest classification of gastroduodenal ulcers causing upper gastrointestinal bleeding, using gastroenterologist consensus as the reference standard. Methods: We conducted a retrospective cohort study using 109 high-quality endoscopic images of gastroduodenal ulcers from esophagogastroduodenoscopy between January 1 and May 15, 2025, in patients with upper gastrointestinal bleeding. Ulcers were classified by consensus of two gastroenterologists (gold standard) and evaluated by ChatGPT-4o using standardized prompts. We calculated the overall accuracy of ChatGPT-4o in classifying ulcers based on the Forrest classification and location of ulcer compared to expert endoscopists using Python version 3.11 (pandas, skipy, scikit-learn). To assess the reliability of ChatGPT-4o’s performance, Cohen’s Kappa coefficient and Intraclass Correlation was utilized. Statistical significance was established at a p-value of less than 0.05. The performance metrics including F1-score and accuracy was presented within the context of a confusion matrix, comprising True Positives, True Negatives, False Positives, and False Negatives. Results: ChatGPT-4o correctly identified the anatomical location (e.g., gastric vs. duodenal) in 77.9% of cases, showing fairly good performance in spatial identification. However, the accuracy in identifying correct Forrest class of ulcer was 39.4%. It performed best on low-risk bleeding (Forrest class 3 and 2c) ulcers and poorly or not at all on high-risk bleeding lesions (Forrest class 1a and 1b) (Binary Accuracy: 77.98%, p-value: 0.00046). ChatGPT-4o’s agreement with human experts is limited, especially for urgent bleeding cases (Cohens Kappa 0.209). It performed similarly for gastric and duodenal ulcers, with slightly better accuracy in duodenal ulcers (40% vs 38.2%). Discussion: ChatGPT-4o has much better performance in identifying low-risk ulcers. It struggles with sensitivity (recall) for high-risk bleeding ulcers, which is critical for clinical triage. This was likely due to underrepresentation or image ambiguity. It matched the expert gastroenterologists’ classification in only ~4 out of 10 cases. This suggests moderate to low reliability in grading ulcers by Forrest criteria.
Figure: Figure 1A: Confusion matrix of risk classification (High vs. Low) heatmap showing the agreement between ChatGPT-4o and expert gastroenterologists in classifying ulcers as high-risk or low-risk; 1B: Forrest classification accuracy by ulcer location; 1C: Performance metrics bar plots by risk group comparing precision, recall, and F1-score for high- and low-risk ulcer classification.
Figure: Figure 2: Summary table of performance metrics of ChatGPT-4o compared to standard gastroenterologists.
Disclosures: Taha Bin Arif indicated no relevant financial relationships. Tahir Shaikh indicated no relevant financial relationships. Bedoor Alabbas indicated no relevant financial relationships. Ruchita Jadhav indicated no relevant financial relationships. Nimra Hasnain indicated no relevant financial relationships.
Taha Bin Arif, MBBS, MD1, Tahir Shaikh, MD1, Bedoor Alabbas, MD1, Ruchita Jadhav, MBBS, MD, MPH1, Nimra Hasnain, MBBS, MD2. P3062 - AI Meets Endoscopy: Assessing ChatGPT-4o’s Accuracy in Gastroduodenal Ulcer Classification and Localization, ACG 2025 Annual Scientific Meeting Abstracts. Phoenix, AZ: American College of Gastroenterology.

 photo")