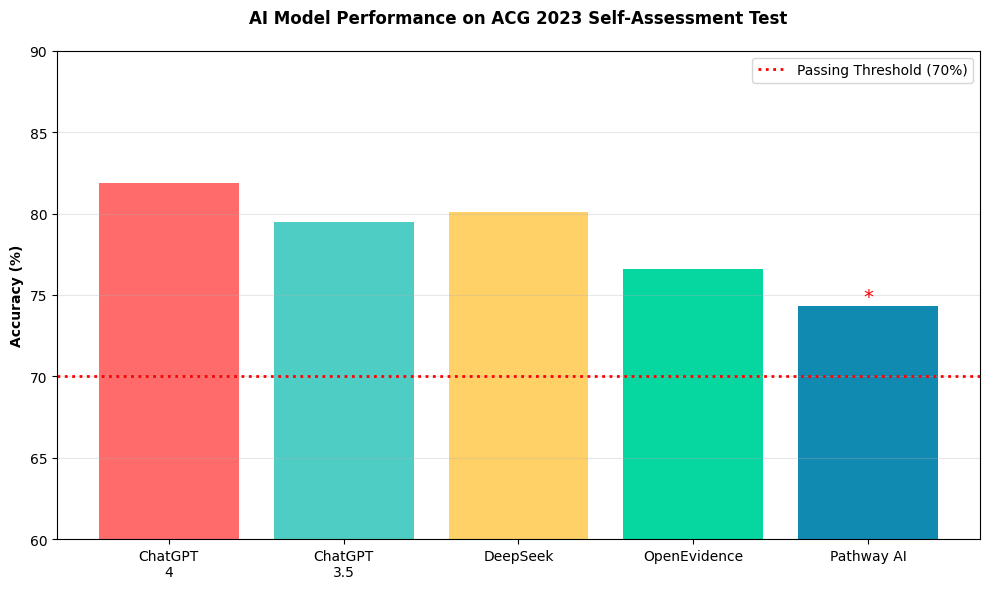
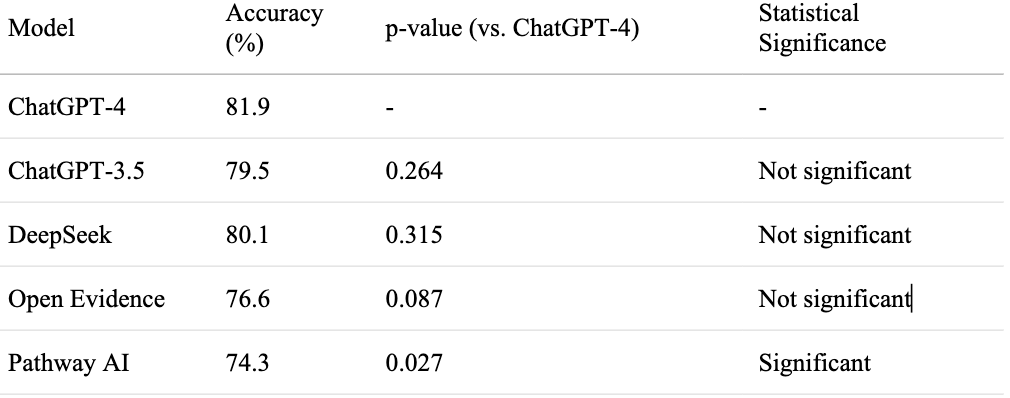
Sufyan AbdulMujeeb, DO1, Hamid Rahman, MD2, Ahmed Khattab, MD, MRCP3, Eli Ehrenpreis, MD, FACG3 1Advocate Lutheran General, Niles, IL; 2Advocate Illinois Masonic Medical Center, Chicago, IL; 3Advocate Lutheran General, Park Ridge, IL Introduction: Large language models (LLMs) are increasingly used in clinical education and decision-making, yet their comparative accuracy on specialty board-style assessments remains unclear. Our objective was to compare the performance of general-purpose and medically specialized LLMs using the 2023 American College of Gastroenterology (ACG) Self-Assessment Exam. Methods: A total of 171 text-based multiple-choice questions from the 2023 ACG Self-Assessment were administered to five LLMs: ChatGPT Free (GPT-3.5), ChatGPT Paid (GPT-4), DeepSeek, Open Evidence, and Pathway AI. Image-based questions were excluded. Each model was evaluated independently. Responses were scored as correct (1) or incorrect (0). Accuracy was calculated as the percentage of correct answers. Pairwise comparisons to GPT-4 were analyzed using two-proportion z-tests with significance set at p < 0.05 Results: GPT-4 achieved the highest score (81.9%), followed by DeepSeek (80.1%), GPT-3.5 (79.5%), Open Evidence (76.6%), and Pathway AI (74.3%). The only statistically significant difference was between GPT-4 and Pathway AI (p = 0.027). Differences between GPT-4 and the other three models were not statistically significant Discussion: All five LLMs surpassed the 70% threshold typically considered passing on the ACG Self-Assessment. General-purpose models, particularly GPT-4, performed comparably to or better than domain-specific alternatives. These findings support the potential utility of generalist LLMs in medical education, though further study is needed to assess their role in broader clinical applications. AI tools were used to run statistical analysis and create graphs & tables depicted in this study.
Figure: Figure 1 presents a bar graph that delineates the differential performance of five AI models on the ACG 2023 Self-Assessment, with accuracy thresholds and statistical significance explicitly annotated
Figure: Table 1 presents the precise accuracy metrics for each evaluated large language model on the ACG 2023 Self-Assessment examination
Disclosures: Sufyan AbdulMujeeb indicated no relevant financial relationships. Hamid Rahman indicated no relevant financial relationships. Ahmed Khattab indicated no relevant financial relationships. Eli Ehrenpreis: E2Bio Consultants – CEO. E2Bio Life Sciences – CEO.
Sufyan AbdulMujeeb, DO1, Hamid Rahman, MD2, Ahmed Khattab, MD, MRCP3, Eli Ehrenpreis, MD, FACG3. P6176 - Battle of AIs: Benchmarking LLMs for Medical Personnel, ACG 2025 Annual Scientific Meeting Abstracts. Phoenix, AZ: American College of Gastroenterology.