
Tuesday Poster Session
Category: Colon
 photo")
Nakul Ganju, MD (he/him/his)
Department of Medicine, Howard University Hospital
Washington, DC
Nine evaluators (3 attendings, 6 fellows) rated chatbot responses to 8 post-colonoscopy questions across four domains. ChatGPT achieved the highest mean score for usefulness (3.71), Copilot for clarity (3.69), and Gemini for accuracy (3.61); empathy consistently rated lowest across platforms, with Gemini receiving the lowest score (3.26). Despite domain-specific variation, no statistically significant differences were found in overall performance (ANOVA p=0.677; all pairwise p >0.4). Attendings and fellows showed strong inter-rater agreement and consistent ranking patterns. These findings suggest comparable overall quality among the chatbots, with minor variation in communication attributes relevant to patient care.
Discussion: This study demonstrates that leading AI chatbots can generate clinically appropriate, patient-friendly responses to routine post-colonoscopy questions. ChatGPT and Copilot, both GPT-4–based, performed slightly better overall, especially in clarity and usefulness. However, limitations in empathy suggest that while chatbots may assist in patient education, they cannot yet replicate the nuance of human interaction. Consistent evaluator scores across training levels support reproducibility and generalizability. These findings support AI chatbots as adjuncts to post-procedure care, with appropriate oversight to ensure safe and effective communication.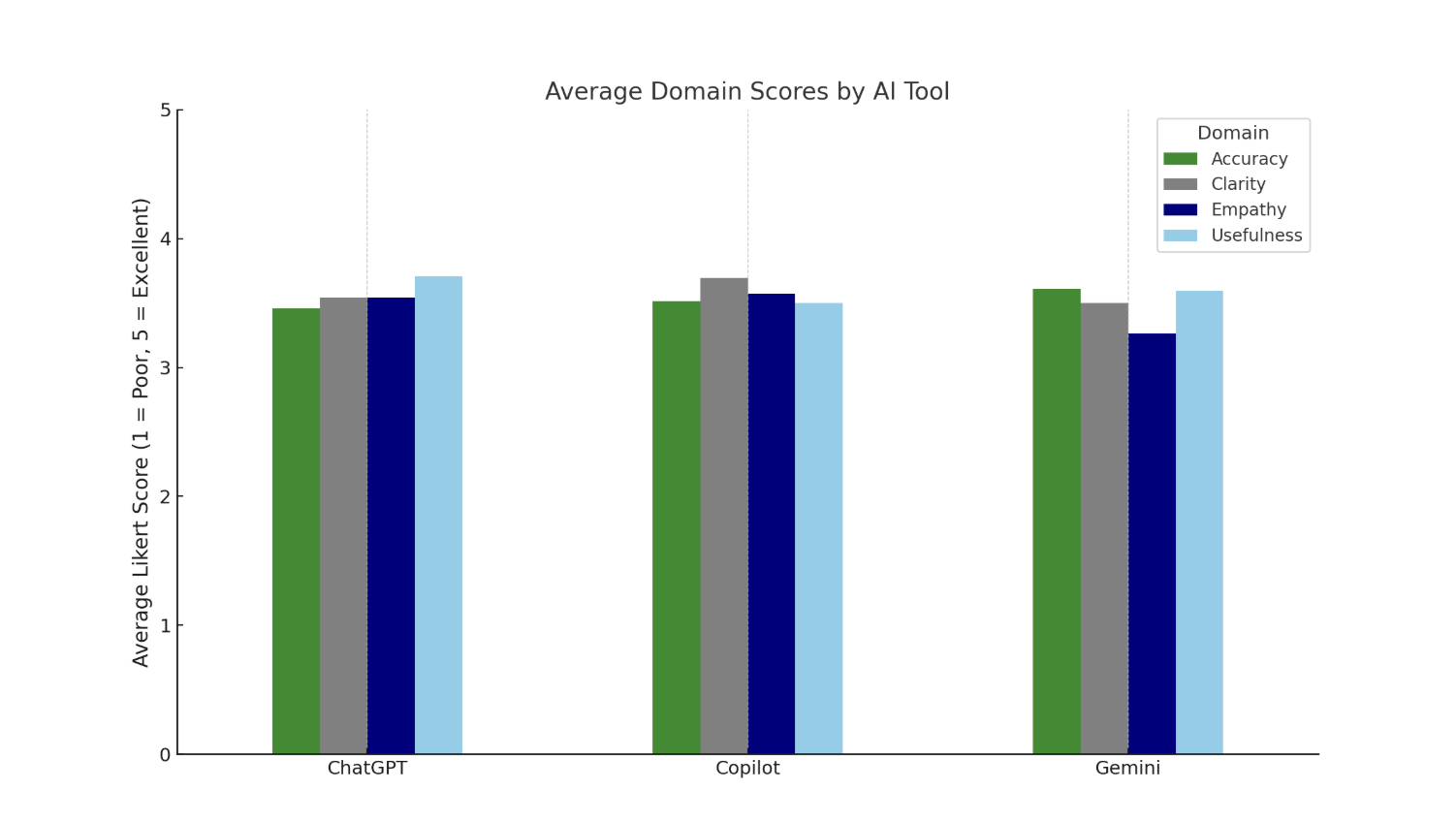
Figure: Figure 1. Post-Colonoscopy Patient Education Response Evaluation Questionnaire used to assess AI chatbot performance across eight commonly asked patient questions regarding post-procedural care.
Figure: Figure 2. Average domain scores for each AI chatbot (ChatGPT, Copilot, and Gemini) across four evaluation categories: Accuracy (forest green), Clarity (grey), Empathy (navy blue), and Usefulness (sky blue). Ratings were based on a 5-point Likert scale (1 = poor, 5 = excellent) aggregated from 9 evaluators (3 attendings, 6 fellows). The figure illustrates relative strengths in each domain, with no statistically significant differences in overall performance among the AI tools.
Disclosures:
Nakul Ganju indicated no relevant financial relationships.
Ahmed Mohamed Ebeid indicated no relevant financial relationships.
Lakshmi Chirumamilla indicated no relevant financial relationships.
Pinky Bai indicated no relevant financial relationships.
Abay Gobezie indicated no relevant financial relationships.
Sean Parker indicated no relevant financial relationships.
Farshad Aduli indicated no relevant financial relationships.
Nakul Ganju, MD1, Ahmed Mohamed Ebeid, MD2, Lakshmi Chirumamilla, MD2, Pinky Bai, MD2, Abay Gobezie, MD2, Sean Parker, BS3, Farshad Aduli, MD2. P4593 - AI-Care: Comparative Evaluation of ChatGPT, Copilot, and Gemini for Post-Colonoscopy Patient Education, ACG 2025 Annual Scientific Meeting Abstracts. Phoenix, AZ: American College of Gastroenterology.