Florida State University College of Medicine/ Sarasota Memorial Hospital Sarasota, FL
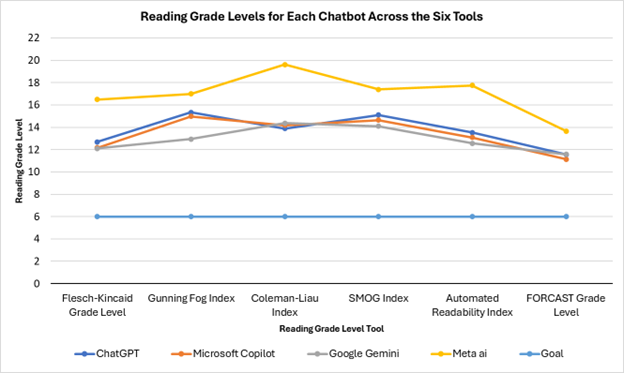
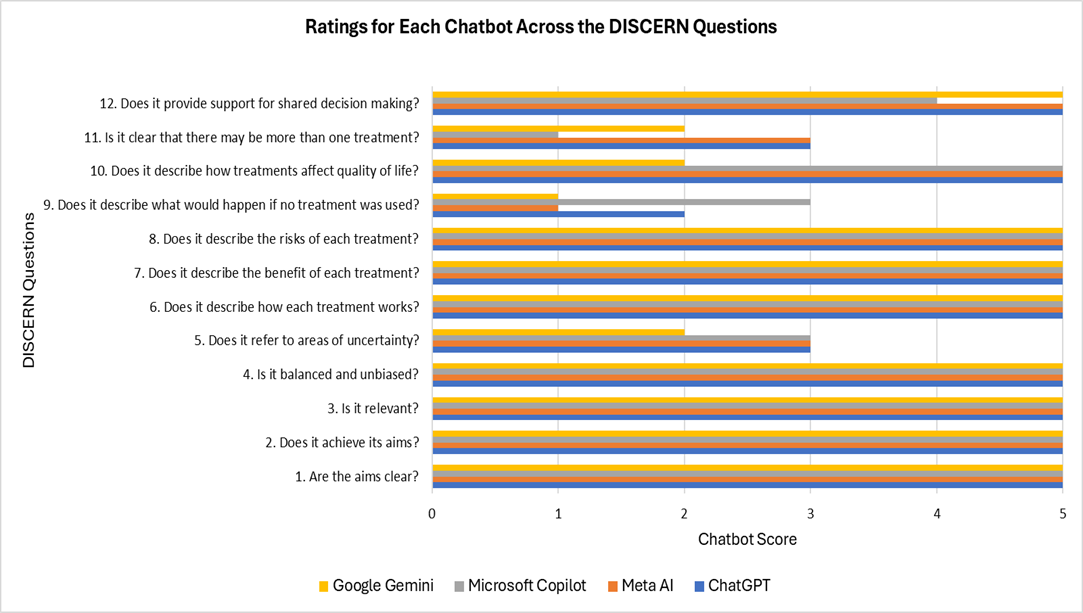
Matthew Miller, DO, Rumit Mistry, DO, William Hixson, BS, Benjamin Behers, MD, Karen Hamad, MD, Gustavo Ramos Ortiz, MD, David Jerez Diaz, MD Florida State University College of Medicine/ Sarasota Memorial Hospital, Sarasota, FL Introduction: Artificial intelligence (AI), particularly large language model (LLM) chatbots, is increasingly used to generate patient education materials (PEM). While AI-generated PEM is generally high quality, its readability is often poor. The utility of AI-generated PEM for Endoscopic Retrograde Cholangiopancreatography (ERCP) has not been thoroughly investigated. This study aims to evaluate the quality and readability of AI chatbot-generated PEM for ERCP. Methods: Ten questions related to ERCP were formulated based on existing website PEM. These questions were submitted sequentially to four widely used chatbots: ChatGPT-4o, Microsoft Copilot, Google Gemini, and Meta AI. Readability was assessed using the Flesch Reading Ease Score (FRES) and six grade-level metrics: Flesch-Kincaid Grade Level (FKGL), Gunning Fog Index (GFI), Coleman-Liau Index (CLI), Simple Measure of Gobbledygook (SMOG), Automated Readability Index (ARI), and FORCAST. Quality was evaluated using two validated PEM tools: a modified DISCERN questionnaire and a modified Patient Education Materials Assessment Tool (PEMAT). Results: The mean FRES across all chatbots was 32.16. Individual FRES scores were 39.45 for ChatGPT, 40.3 for Microsoft Copilot, 38.08 for Google Gemini, and 10.81 for Meta AI. The overall mean grade levels across the six readability tools were 13.37 (FKGL), 15.06 (GFI), 15.52 (CLI), 15.31 (SMOG), 14.24 (ARI), and 11.99 (FORCAST). Mean reading grade levels for each chatbot across the six tools were 13.69 for ChatGPT, 13.37 for Microsoft Copilot, 12.94 for Google Gemini, and 16.98 for Meta AI. In the reliability section of the DISCERN questionnaire, all chatbots scored 4.6, except for Google Gemini, which scored 4.4. For the quality section of the DISCERN questions, ChatGPT scored 4.29, Meta AI 4.14, Microsoft Copilot 4.0, and Google Gemini 3.57. Regarding PEMAT scores, ChatGPT and Google Gemini achieved 100% for understandability, while Microsoft Copilot and Meta AI scored 91.6%. All chatbots scored 75% for the actionability portion of the PEMAT questionnaire. Discussion: This study shows AI chatbots can generate high-quality PEM for ERCP, but readability is poor. For better patient understanding and adherence, chatbot-generated PEM should aim for a sixth-grade reading level. However, responses averaged about twice the target level. While chatbot use is not discouraged, providers should inform patients of limits in readability. Future research should develop and test AI tools engineered for patient-centric language.
Figure: A bar chart was created in Microsoft Excel, representing individual chatbot DISCERN scores (x-axis) for each question (y-axis) from our modified DISCERN tool. Questions 1-5 pertain to the reliability of the chatbot responses. Questions 6-12 pertain to the quality of information in the chatbot responses.
Figure: A line chart, representing readability scores (y-axis) of chatbot-created material across six different tools (x-axis), was created using Microsoft Excel.
Disclosures: Matthew Miller indicated no relevant financial relationships. Rumit Mistry indicated no relevant financial relationships. William Hixson indicated no relevant financial relationships. Benjamin Behers indicated no relevant financial relationships. Karen Hamad indicated no relevant financial relationships. Gustavo Ramos Ortiz indicated no relevant financial relationships. David Jerez Diaz indicated no relevant financial relationships.
Matthew Miller, DO, Rumit Mistry, DO, William Hixson, BS, Benjamin Behers, MD, Karen Hamad, MD, Gustavo Ramos Ortiz, MD, David Jerez Diaz, MD. P1917 - Assessing the Quality and Readability of AI Chatbot-Generated Patient Education Materials for Endoscopic Retrograde Cholangiopancreatography, ACG 2025 Annual Scientific Meeting Abstracts. Phoenix, AZ: American College of Gastroenterology.